Perhaps it is just me, but I found that it was just a bit too confusing to understand how to do a Bayesian meta-analysis when I was first starting. There were a variety of packages and methods, all seemingly not documented to my satisfaction. Eventually I would find some better sources, but that took so long after search engine algorithms “helped” me.
So, I feel like it is probably not the worst idea to provide a good example of a meta-analysis using Bayesian methods, something that is similar to what I would actually do when conducting a single meta-analysis for a real project (at least the basic process). That is the goal of this post. Just a simple introduction to a general, Bayesian meta-analysis application.
I’ll mostly focus on the use of brms, but code for everything is included here in drop-down tabs.
NoteLog Scale
In this post I repeatedly mention “Log Scale.” I am referencing natural log, not a base 10 logarithm. If you are still getting used to R, remember that in R, log(x) is the natural log (\(ln(x)\)), exp(x) is \(e^{(x)}\). R has no ln().If I say ‘log’ in these notes, I mean natural log.
Meta-Analysis with BRMS
I am going demonstrate this analysis with the R package brms, which is an R package that interfaces with Stan - the actual code of the model. brms (as well as RStan and RStanarm) are intended to be more intuitive interfaces, using syntax you could be familiar with from other R language and packages (metafor and bayesmeta are also worth mentioning - all great at what they do, all with specific limitations). However, as I will show in another post… You can also just use CmdStanR to pass code directly to Stan and skip all of that if you aren’t afraid of Stan code. In any case, here is a brief explanation of what is happening in my brms code and model:
# Fit the model - output as "meta_analysis_model"meta_analysis_model <-brm(formula = log_RR |se(SE_log_RR) ~1+ (1| study),data = sim_data2,family =gaussian(),prior =c(prior(normal(-0.2, 2), class = Intercept),prior(cauchy(0, 0.8), class = sd)),iter =4000, warmup =2000, cores =4, chains =4)
The function brm() encapsulates all of our input - model, parameters, and running conditions. It is the brms function that takes that input and runs the model, the Bayesian regression model (thus, brm).
formula = y | se(SE_log_RR) = 1 + (1 | trial_name) is the code representation of the regression model that we want to specify - and likely the most complex part. This model is often represented by something like this:
\[
first \ stage: y_i \sim N(\theta_i, s^2_i) \\
second \ stage: \theta_i \sim N(\mu,\tau^2)
\]
where the first stage represents the observed effect for each study (\(y_i\)) and its theoretical distribution, and then the second stage represents the true effect (\(\theta_i\)) of each separate study, and \(s^2_i\) is the variance for each study. The simpler marginal form would then be:
\[
y_i \sim N(\mu, s^2_i + \tau^2)
\]
Of note, this model assumes a different true effect for each study as opposed to an absolute true estimate.
In the formula line, | se(sei) is how I indicate to brms that I am conducting a meta-analysis, and that sei is the observed standard error (SE) for my study effect estimates Y. brms can then use this SE to weight the study results by precision and estimate the posterior for \(\tau\).
Additionally, the right side of the the equation, 1 + (1 | trial_name), tells brms that I want an intercept only model and that I want the intercept to vary by trail_name. There are no predictor variables, only a 1, Within the code (1 | trial_name), the 1 indicates random intercepts, and the trial_name tells brms that I want intercepts that vary by the variable trial_name.
data = mreg_data specifies the dataset I intend to use in my model.
family = gaussian() shows that I am specifying a Gaussian link function between our left and right of the model equals sign, and also specifies a Gaussian response distribution. This results in a normal-normal hierarchical model. Notably, one can only choose certain families in brms that have the ability to conduct meta-analysis - Gaussian and only two other model types allow the se() option.
prior = c(...) lists all of our prior specifications where:
prior(normal(-0.2, 2), class = Intercept) is the prior for our intercept, \(\mu_{prior}\sim \mathbf{N} (-0.2, 2)\).
prior(cauchy(0, 0.8), class = sd) is the prior I selected for \(\tau\), the heterogeneity between studies. It’s specified as a standard deviation via class = sd, and we use the distribution \(\tau_{prior} \sim \mathbf{Cauchy}(0, 0.8)\). This will actually result in a half-Cauchy distribution, which is often found to be reasonable as a prior for heterogeneity (it’s is a special case of the t distribution where degrees of freedom = 1 and only positive values are allowed). We’ll explore more later, but in general we wantweakly informative priors.1
iter = 4000 shows the number of iterations per chain when conducting likelihood estimation. Brms uses the No-U Turn Sampler (NUTS) by default, but other methods are available.
warmup = 2000 indicates the number of “burn-in” estimates you would like to throw out, after which you should have a stable chain (a stable chain is sometimes called a “fuzzy caterpillar”).
cores = 4 does exactly what you would think - we’re partitioning cores for parallelization.
chains = 4 is where I have specified the number of estimate chains that are being used, i.e., the number of separate estimations for the likelihood I am running at one time.
Given that we are modelling the standard error between studies, and have a random effect by study, this model estimates the random effect model.
This is specifically done through including the se() option as I mentioned above - without this specification you aren’t really doing a meta-analysis.
I should also point out that Bayesian regression has an ability to use multiple likelihood forms and conjugate families to estimate or approximate the likelihood and thus the posterior. However, the normal-normal hierarchical model is most common. It’s efficient given we work on the log scale for our model, and is also one of the more intuitive forms of Bayesian regression.
Note
The example given here shows a random effects meta-analysis model conducted in brms. There are a variety of packages and ways to accomplish this in R, but this is a common, robust way.
The model is ultimately \(y_i \sim N(\mu, s^2_i + \tau^2)\), with our primary interest being \(\mu\), the overall effect estimate.
\(\tau\) is also important - it represents the heterogeneity between studies via the overall SE.
The example here is using a normal-normal hierarchical model, and will operate with log-transformed data.
Data Simulation and First Model
Here, I am going to simulate some data for example use, and then go ahead and apply the meta-analysis model we went over in the previous section. Let’s pretend that we have fifteen studies, trials in which we are examining the RR between treatment and placebo (or some other comparator), with outcomes being an adverse phenomenon of some sort - we are looking to see if treatment is associated in a reduction of negative effects of disease or not. Here’s the data simulation:
Code
library(tidyverse)library(gt)set.seed(1234)k <-15# Number of studies# Assume the true RR is 0.75 → meanlog = log(0.75)meanlog <-log(0.75)sdlog <-sqrt(0.1) # Between-study SD on log scale# Simulate RR values directly from log-normal distributionRR_i <-rlnorm(k, meanlog = meanlog, sdlog = sdlog)# Simulate SEs for log(RR) (affects CI width)SE_logRR <-runif(k, min =0.1, max =0.5)# Compute CI bounds on log scalelogRR_i <-log(RR_i)CI_lower_log <- logRR_i -1.96* SE_logRRCI_upper_log <- logRR_i +1.96* SE_logRR# Convert CIs back to RR scaleRR_lower <-exp(CI_lower_log)RR_upper <-exp(CI_upper_log)# Put it all in a data framesim_data <-data.frame(study =paste0("trial ", 1:k),RR = RR_i,RR_lower = RR_lower,RR_upper = RR_upper)sim_data %>%gt() %>%fmt_number(columns =c(study, RR, RR_lower, RR_upper),decimals =2 ) %>%cols_label(study ="study",RR ="Rate Ratio",RR_lower ="95% CI Lower",RR_upper ="95% CI Upper" ) %>%tab_header(title ="Simulated Rate Ratios from 15 Trials",subtitle ="With 95% Confidence Intervals" )
Simulated Rate Ratios from 15 Trials
With 95% Confidence Intervals
study
Rate Ratio
95% CI Lower
95% CI Upper
trial 1
0.51
0.29
0.89
trial 2
0.82
0.55
1.23
trial 3
1.06
0.68
1.63
trial 4
0.36
0.20
0.65
trial 5
0.86
0.61
1.20
trial 6
0.88
0.40
1.94
trial 7
0.63
0.44
0.89
trial 8
0.63
0.42
0.94
trial 9
0.63
0.24
1.66
trial 10
0.57
0.25
1.30
trial 11
0.64
0.34
1.21
trial 12
0.55
0.27
1.10
trial 13
0.59
0.38
0.91
trial 14
0.77
0.39
1.52
trial 15
1.02
0.64
1.60
It is common for results to be reported in the form of point estimate and 95% confidence interval. Since we need the SE of study results to feed into brms, we will need to calculate the standard error from the confidence interval and the point estimate. We also will choose to work in the log scale when modelling, so here we can go straight to the log-transform SE via:
In the following R code I will apply this formula, as well as take the natural log of the estimates so that we are prepared for our log scale model:
Code
sim_data2 <- sim_data %>%mutate(log_RR =log(RR),SE_log_RR = (log(RR_upper) -log(RR_lower)) / (2*1.96) )sim_data2 %>%gt() %>%fmt_number(columns =c(study, RR, RR_lower, RR_upper, log_RR, SE_log_RR),decimals =3 ) %>%cols_label(study ="Study",RR ="Rate Ratio",RR_lower ="95% CI Lower",RR_upper ="95% CI Upper",log_RR ="Ln(RR)",SE_log_RR ="SE of ln(RR)" ) %>%tab_header(title ="Simulated Rate Ratios from 15 Trials",subtitle ="Now With Logarithmic Transform" )
Simulated Rate Ratios from 15 Trials
Now With Logarithmic Transform
Study
Rate Ratio
95% CI Lower
95% CI Upper
Ln(RR)
SE of ln(RR)
trial 1
0.512
0.294
0.891
−0.669
0.282
trial 2
0.819
0.547
1.226
−0.200
0.206
trial 3
1.057
0.684
1.632
0.055
0.222
trial 4
0.357
0.197
0.647
−1.029
0.303
trial 5
0.859
0.613
1.204
−0.152
0.172
trial 6
0.880
0.399
1.942
−0.128
0.404
trial 7
0.625
0.439
0.891
−0.469
0.180
trial 8
0.631
0.423
0.940
−0.461
0.204
trial 9
0.627
0.237
1.661
−0.466
0.497
trial 10
0.566
0.247
1.297
−0.569
0.423
trial 11
0.645
0.344
1.211
−0.439
0.321
trial 12
0.547
0.271
1.104
−0.603
0.359
trial 13
0.587
0.378
0.911
−0.533
0.225
trial 14
0.765
0.386
1.516
−0.267
0.349
trial 15
1.016
0.645
1.600
0.016
0.232
NoteNote: Standard Error and Log Scale
This common definition of standard error is dependent upon scale, and you cannot simply go from log-scale standard error to identity-scale SE. Id est, \(exp(SE_{log(RR)}) \neq SE_{RR}\).
You need to either exponentiate the log-scale values for the estimate and 95% confidence interval and then calculate SE as done here, or use the Delta method - the latter is probably not the best use of your time.
Priors
It wouldn’t be a Bayesian analysis if I didn’t examine the priors, so let’s compare a few normal priors for our overall effect estimate (our Intercept prior) and our heterogeneity (the sd prior).
These priors have been discussed in a number of sources concerning what distributions to choose.1,2 I will just focus on the most likely to be applicable - the half Cauchy and lognormal distributions for our values of \(\tau\), and a normal distribution for our prior values of \(ln(\mu)\). Remember - we log transformed \(\mu\) so that it would be normally distributed in our normal-normal hierarchical model.
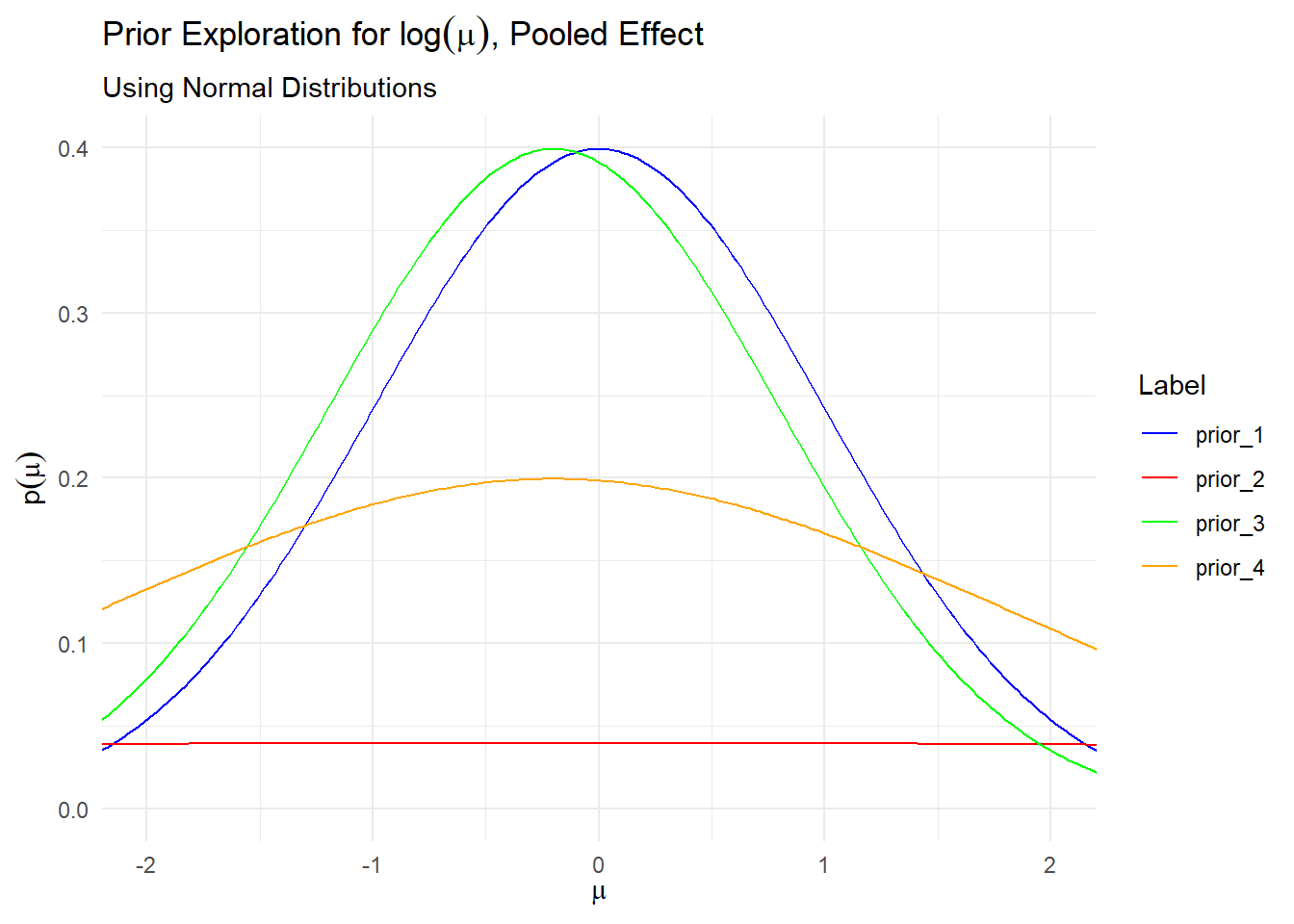
Let’s explore these potential priors. First, our prior for \(\mu\); this should be fairly simple given that we have an idea about what effects to logically expect. We would expect that our treatment works to some extent, but it may also be helpful to have a bit more of the density in the tail of the distribution. This gives our prior some uncertainty that we want, hopefully reducing our chances of biasing the likelihood. Let’s plot a few different normal densities to see which one makes the most sense:
Code
#note - yes I know this isn't "tidy." I don't care and I find the "tidyverse" idiosyncratic and not how people think about data or use data, or how any other statistical packages operate. However, the tidyverse recommendation is to put the data in long format and then ggplot works with less code.# Define the grid of x values (positive, since lognormal is > 0)x_vals <-seq(-5, 5, length.out =500)prior_1 <-dnorm(x_vals, mean =0, sd =1)prior_2 <-dnorm(x_vals, mean =-0.2, sd =10)prior_3 <-dnorm(x_vals, mean =-0.2, sd =1)prior_4 <-dnorm(x_vals, mean =-0.2, sd =2)plot_data <-as.data.frame(cbind(x_vals, prior_1, prior_2, prior_3, prior_4) )# Plotggplot() +geom_line(data = plot_data, aes(x = x_vals, y = prior_1, color ="prior_1")) +geom_line(data = plot_data, aes(x = x_vals, y = prior_2, color ="prior_2")) +geom_line(data = plot_data, aes(x = x_vals, y = prior_3, color ="prior_3")) +geom_line(data = plot_data, aes(x = x_vals, y = prior_4, color ="prior_4")) +scale_color_manual(values =c("prior_1"="blue", "prior_2"="red", "prior_3"="green", "prior_4"="orange")) +labs(color ="Label") +coord_cartesian(xlim =c(-2, 2)) +labs(title =expression("Prior Exploration for "*log(mu) *", Pooled Effect"),subtitle ="Using Normal Distributions",x =expression(mu),y =expression(p(mu)) ) +theme_minimal()
Let’s say we think that there is a higher probability of the true effect being protective, which due to the log transform that probably puts us in the negative range here, just slightly, so I don’t like Prior 1 as much. We also have the option to be very vague and choose something like Prior 2 here, which some advocate for (or even a uniform distribution) but I prefer to be weakly informative. I like Prior 4 and will use that one. I also want a decent probability it could be between -1 and 1 on the log scale. Let’s pretend I don’t believe the chances of the effect being outside of that range makes sense when I am thinking about the potential effects our simulated medication might have.
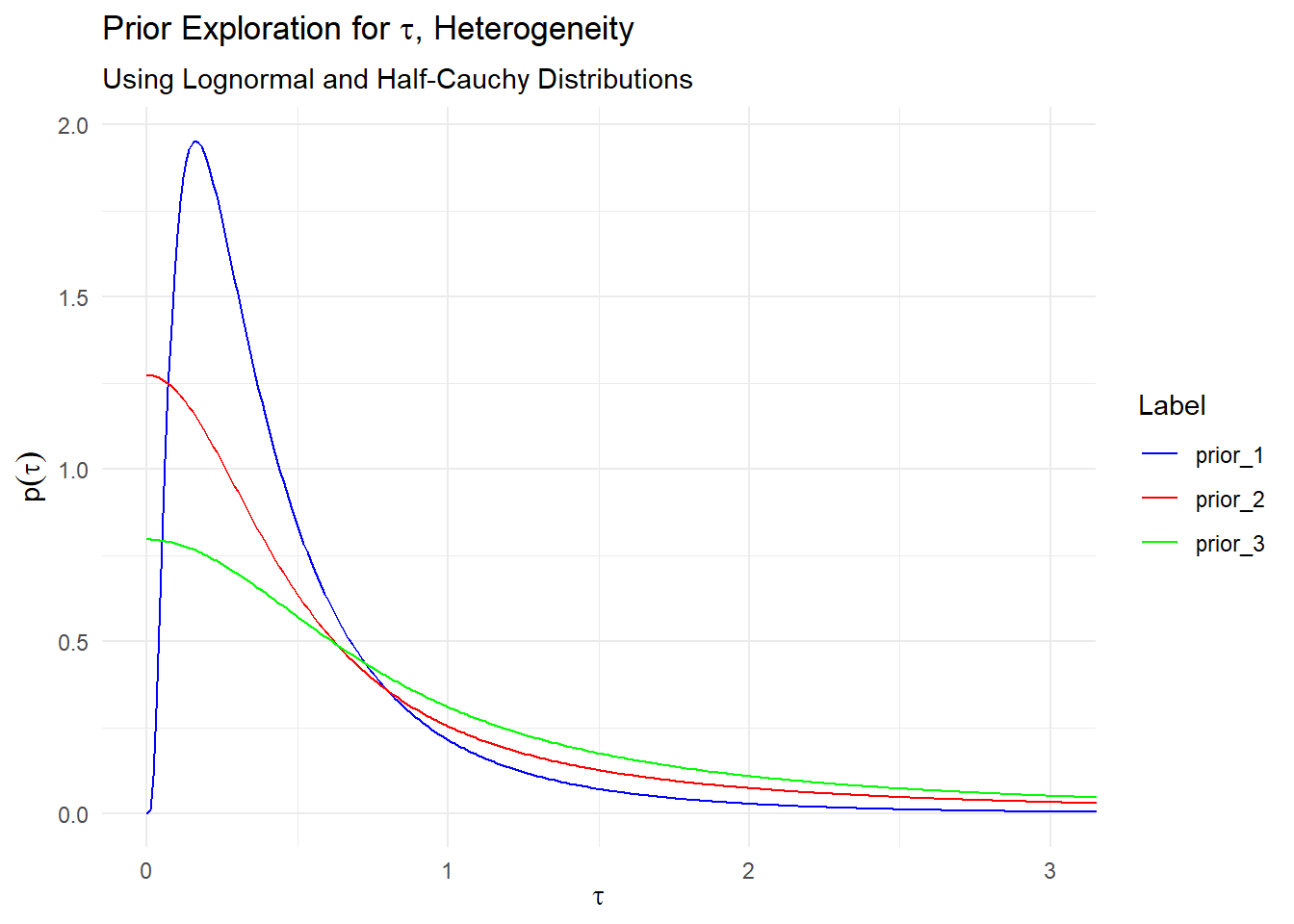
Next let’s examine some priors for \(\tau\). Common choices are either a half-Cauchy or log-normal distribution, so let’s explore those just a bit.
Code
# Define the grid of x values (positive, since lognormal is > 0)x_vals <-seq(0.00001, 5, length.out =500)prior_1 <-dlnorm(x_vals, meanlog =-1.07, sdlog =0.87)prior_2 <-ifelse(x_vals >=0, 2*dcauchy(x_vals, location =0, scale =0.5), 0) prior_3 <-ifelse(x_vals >=0, 2*dcauchy(x_vals, location =0, scale =0.8), 0)plot_data <-as.data.frame(cbind(x_vals, prior_1, prior_2, prior_3) )# Plotggplot() +geom_line(data = plot_data, aes(x = x_vals, y = prior_1, color ="prior_1")) +geom_line(data = plot_data, aes(x = x_vals, y = prior_2, color ="prior_2")) +geom_line(data = plot_data, aes(x = x_vals, y = prior_3, color ="prior_3")) +scale_color_manual(values =c("prior_1"="blue", "prior_2"="red", "prior_3"="green")) +labs(color ="Label") +coord_cartesian(xlim =c(0, 3)) +labs(title =expression("Prior Exploration for "* tau *", Heterogeneity"),subtitle ="Using Lognormal and Half-Cauchy Distributions",x =expression(tau),y =expression(p(tau)) ) +theme_minimal()
Prior 3, with a scale parameter of 0.8, seems fairly reasonable. It has a bit of a wider tail and is thus less informative, and it gives our heterogeneity less of a chance to be 0. More informative is the lognormal distribution in prior 1 - this is very reasonable if we really think there will be some heterogeneity in our studies, but we still want to have a decent tail. Prior 2 is often suggested as reasonable in literature, but let’s say I want to be just a bit more conservative, so I’m choosing Prior 3.
Note
Always consider what priors logically make sense given your analysis
For meta-analysis, it is common to use weakly informative priors or completely vague priors, often with a normal distribution for the observations prior, and something like a half-Cauchy or lognormal distribution for the heterogeneity prior. It may be helpful to start examining priors with these distributions.
Results
With the selection of the priors, the model is ready to go!
Here is the output with these priors, the observations simulated earlier, their SEs, and Bayesian estimation:
Code
library(brms)library(posterior)library(bayestestR)# Fit the model - output as "meta_analysis_model"meta_analysis_model <-brm(formula = log_RR |se(SE_log_RR) ~1+ (1| study),data = sim_data2,family =gaussian(),prior =c(prior(normal(-0.2, 2), class = Intercept),prior(cauchy(0, 0.8), class = sd)),iter =4000, warmup =2000, cores =4, chains =4)#get summary estimates from model output: (can alternatively use the "posterior" package and draws)results <-posterior_summary(meta_analysis_model)#create an array for log-RR results, and for identity (RR) scale resultsrows <-c("Overall effect (log-RR)", "Overall effect (RR)", "Log-scale Tau", "Identity Scale Tau")cols <-c("Estimate", "2.5% Pr", "97.5% Pr")arr <-array(NA_real_, dim =c(length(rows), length(cols)), dimnames =list(rows, cols))# ------ providing identity-scale heterogeneity (a bit more involved) ------ draws <-as_draws_df(meta_analysis_model)log_mu_draws <- draws$b_Interceptlog_tau_draws <- draws$sd_study__Intercepttau_draws <-exp(log_tau_draws)mu_draws <-exp(log_mu_draws)# Calculate SD on RR scale for posterior drawstau <-median(tau_draws)ci_tau_rr <- bayestestR::hdi(tau_draws, ci =0.95)mu <-median(mu_draws)ci_mu_rr <- bayestestR::hdi(mu_draws, ci =0.95)identity_tau <-data.frame(parameter ="tau_rr (identity scale)",median = tau,`2.5%`= ci_tau_rr$CI_low,`97.5%`= ci_tau_rr$CI_high)identity_mu <-data.frame(parameter ="mu_rr (identity scale)",median = mu,`2.5%`= ci_mu_rr$CI_low,`97.5%`= ci_mu_rr$CI_high)# ------ Array & Table Output ------ #input the values from results (I'm just doing this by row)arr[1,] <-c(results[1,1], results[1,3], results[1,4])arr[2,] <-c(identity_mu[1,2], identity_mu[1,3], identity_mu[1,4])arr[3,] <-c(results[2,1], results[2,3], results[2,4])arr[4,] <-c(identity_tau[1,2], identity_tau[1,3], identity_tau[1,4])#create aesthetic tablerope_pd <-describe_posterior(meta_analysis_model, centrality ="median") %>%select(ROPE_Percentage, pd) table <-as.data.frame(arr) %>%rownames_to_column("Parameter") %>%mutate(`(95% CrI)`=sprintf("[%.3f, %.3f]", `2.5% Pr`, `97.5% Pr`)) %>%bind_rows(tibble(Parameter =c("ROPE %", "PD"),Estimate =c(rope_pd$ROPE_Percentage, rope_pd$pd),`2.5% Pr`=NA,`97.5% Pr`=NA,`(95% CrI)`=NA ) )gt(table) %>%cols_hide(columns =c(`2.5% Pr`, `97.5% Pr`)) %>%fmt_number(columns =c(Estimate, `(95% CrI)`),decimals =3 ) %>%tab_header(title ="Results In Identity and Log Scale" )
Results In Identity and Log Scale
Parameter
Estimate
(95% CrI)
Overall effect (log-RR)
−0.358
[-0.528, -0.195]
Overall effect (RR)
0.701
[0.581, 0.813]
Log-scale Tau
0.153
[0.007, 0.377]
Identity Scale Tau
1.152
[1.000, 1.397]
ROPE %
0.000
NA
PD
1.000
NA
At first glance, things appear to be in order. The next step is always to provide compelling visualization. So, next I will demonstrate a Forest plot equivalent - sometimes called a blobbogram, half-eye plot, or raincloud plot. Sometimes you might see something much more like a traditional Forest plot, however we have more information in our Bayesian analysis, so we may as well use it to maximize information and aesthetics.
Note04.08.2025 Update
I updated the code In the model above to show the better method of providing identity scale \(\tau\). There are some relationships which can provide direct estimates, however these are not so robust and can provide strange results in some circumstances. Please note that the preferred way of going from log-form posterior distributions to identity-form (and any other transforms) is to collect draws, transform the draws, and then estimate the parameters. There’s no need to overthink things here.
In essence, take the draws from log-\(\tau\), exponentiate the values to transform the posterior distribution, then find credible intervals or standard errors, etc. This is more robust and safe, and in general easier to accomplish.
For this, I use tidybayes for posterior simulation, and otherwise I use standard tidyverse functions like ggplot().
Code
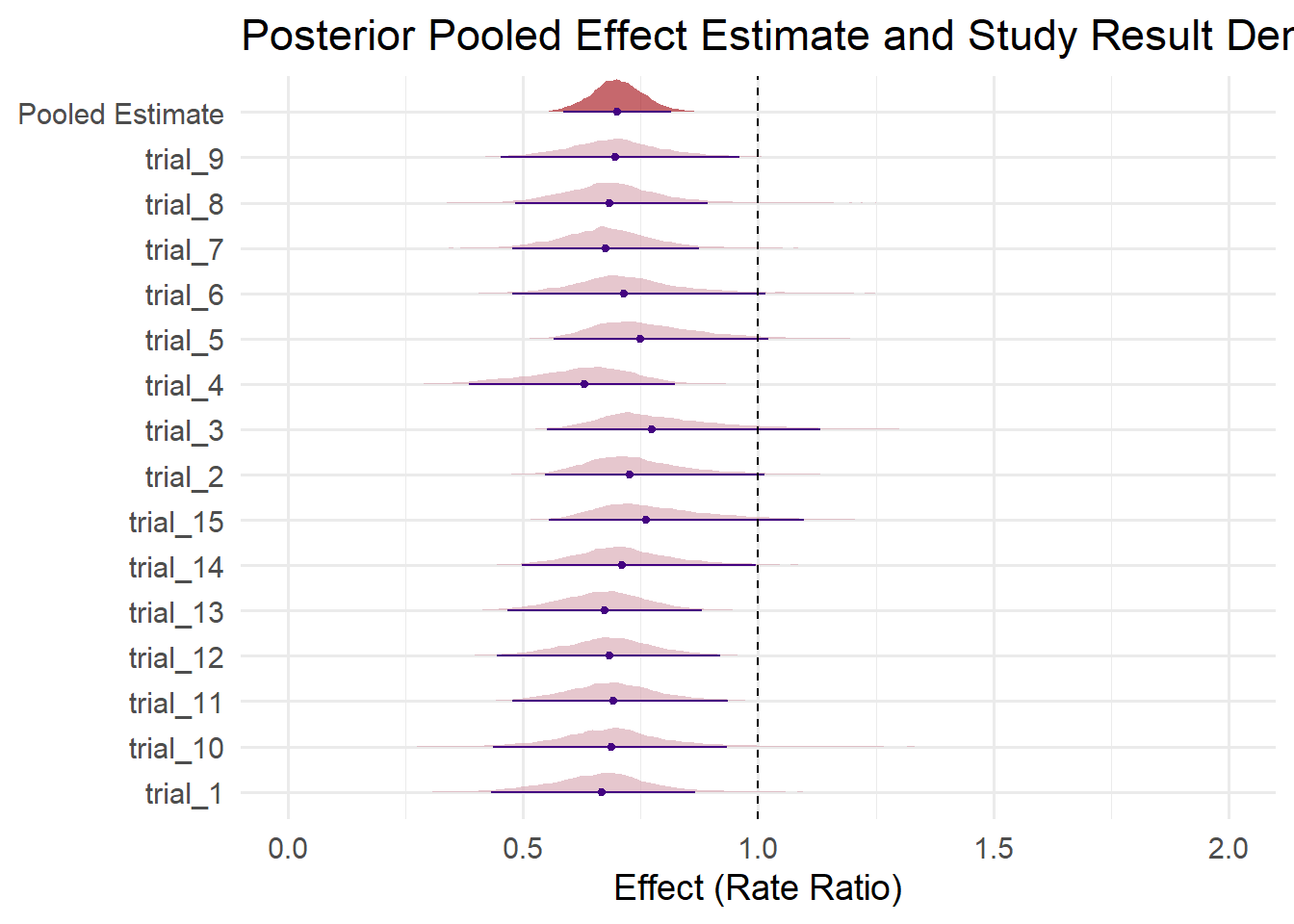
library(tidybayes)# posterior draws for our overall effectpooled_draws <-as_draws_df(meta_analysis_model) %>%select(b_Intercept) %>%mutate(study ="Pooled Estimate",logRR = b_Intercept,RR =exp(logRR) ) %>%select(study, RR)# Extract posterior draws for random effects by study# Note: brms names random effects like r_Study[StudyName,Intercept]study_draws_raw <-as_draws_df(meta_analysis_model) %>%select(starts_with("r_Study")) # Tidy the random effects draws to long formatstudy_draws <- study_draws_raw %>% janitor::clean_names() %>%pivot_longer(cols =everything(),names_to ="param",values_to ="random_effect") %>%mutate(# Extract study names from param stringstudy =str_extract(param, "trial_[0-9]{1,2}"),# Add the fixed intercept to random effect for full logOR posterior per studylogRR = random_effect +as_draws_df(meta_analysis_model)$b_Intercept,RR =exp(logRR) ) %>%select(study, RR)# Combine pooled and study-specific drawsplot_data <-bind_rows( study_draws, pooled_draws)# Make sure "Pooled Estimate" is last for plotting orderplot_data$study <-factor(plot_data$study, levels =c(sort(unique(study_draws$study)), "Pooled Estimate"))# Plot using ggdistggplot(plot_data, aes(x = study, y = RR, fill = (study =="Pooled Estimate"))) +stat_halfeye(adjust =0.5, width =0.8, size =0.5, color ="#440381", .width =0.95, slab_alpha =0.6, point_interval ="median_hdi") +scale_fill_manual(values =c("TRUE"="#A0030B", "FALSE"="#D6A2AD"), guide ="none") +geom_hline(yintercept =1, linetype ="dashed") +coord_flip() +scale_y_continuous(limits =c(0,2)) +labs(title ="Posterior Pooled Effect Estimate and Study Result Densities",x =NULL,y ="Effect (Rate Ratio)" ) +theme_minimal(base_size =14)
Our estimate is a bit more protective (less than 1) than the original true value we used in our simulation of 0.75, but it is not far off and well within our posterior distribution and credible interval. Here, the line and dot at the bottom of each density (or raincloud, or half-eye) represents the highest density interval (HDI) estimated 95% CrI, and the dot marks the median of the posterior estimates after being shrunken to account for heterogeneity.
Note
Remember to use log and identity scales appropriately when working with model and results
Bayesian analysis lends itself well to use of a blobbogram, but a standard Forest plot can also be used.
Examining Heterogeneity
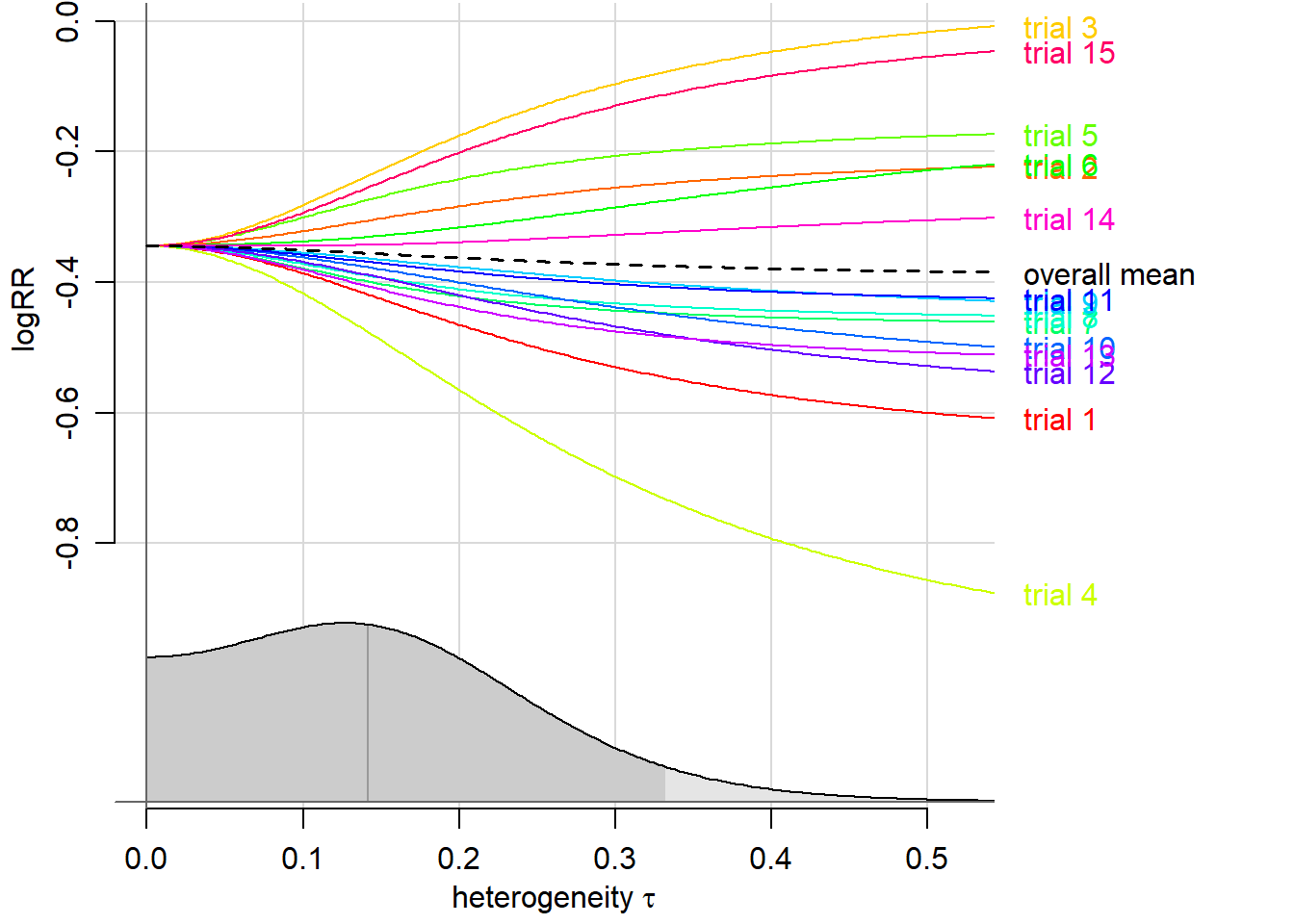
When examining heterogeneity, one could simply use the package metafor to generate a quick funnel plot - a standard approach that is more useful than most realize. However, I should also point out that we have another option with which we can leverage our posterior distribution for \(\tau\). We can create a chart that also goes by many names, sometimes called a “trace plot,” a “conditional shrinkage plot,” or a “conditional means plot.” I’ll stick with conditional means plot, since I think that’s the most straightforward name. Whatever you call it, this is a chart that has the posterior distribution for \(\tau\) at the bottom, and above the conditional means for each study and the pooled mean.3 This shows us the shrinkage of our estimates in relation to \(\tau\), or rather, how our effect estimates are affected by plausible values of heterogeneity across the entire posterior distribution for \(\tau\). Usually we have otherwise overlooked uncertainty in our estimate for \(\tau\), and this functions as a sort of sensitivity analysis to see if that is a major concern in the robustness of our study.
Code
# This is very complicated to do without the help of bayesmeta - I highly suggest it for this. # Note - you can use only one set of draws, but I am including it again here to show the full process.library(bayesmeta)#... bayesmeta does not inherently accomodate Cauchy/half-Cauchy priors, so we have to feed that in.half_cauchy_prior <-function(tau) { scale <-0.82/ (pi * scale * (1+ (tau / scale)^2))}# Fit a random-effects meta-analysisbma <-bayesmeta(y = sim_data2$log_RR,sigma = sim_data2$SE_log_RR,labels = sim_data2$study,tau.prior = half_cauchy_prior)# Plot shrinkage traceplottraceplot(bma, ylab ="logRR")
We can see in our conditional means plot that the median of \(\tau\) is somewhere just below 0.15, and our credible interval is there in the darker shade of grey. Most importantly, we can see that our overall mean, which is \(\mu\), remains nearly the same with respect to the logRR. This is good - if we see that changing as we move from left to right across values of \(\tau\), this tells us that our parameters are sensitive to heterogeneity, which can be problematic since that is part of our likelihood estimate in our model. In other words, if the black dashed line isn’t flat, our model is potentially not valid due to imprecise estimate of \(\tau\).
If the plot shows drastic changes in parameters across \(\tau\), it might be time to explore the cause of heterogeneity and potentially consider meta-regression as a means to address that, or including more studies if possible - both things that might help more better estimates of \(\tau\).3
Note
Use of a trace plot can be more beneficial than a only a funnel plot when examining heterogeneity between studies (and yes, a funnel plot provides more information than only risk of publication bias).
In inference, focus on attained precision rather than hypothesis testing (even if someone is wanting to force the traditional hypothesis testing paradigms)
Postface
It wasn’t until even after I started writing these notes that I discovered a great source - Doing Meta-Analysis with R: A Hands-On Guide. While I only glanced at it so far, it seems like exactly the thing I wish I had in my hands months ago. Most of my information is sourced from articles, and The Handbook of Meta-Analysis, and the R vignettes for the packages used. So, if you have more questions on this, consider giving these sources a skim.
In any case, I hope you learned something, and found that this can be fun and not quite so confusing.
NoteAI Disclaimer
Some of the code used was written with the help (or hindrance) of ChatGPT.
References
1.
Schmid C, Stijnen T, White I. Handbook of Meta-Analysis. CRC Press; 2021.
2.
Turner RM, Jackson D, Wei Y, Thompson SG, Higgins JPT. Predictive distributions for between-study heterogeneity and simple methods for their application in bayesian meta-analysis. Statistics in Medicine. 2015;34:984-998. doi:10.1002/sim.6381
3.
Röver C, Rindskopf D, Friede T. How trace plots help interpret meta-analysis results. Research Synthesis Methods. 2024;15:413-429. doi:10.1002/jrsm.1693
4.
Watt JA, Giovane CD, Jackson D, et al. Incorporating dose effects in network meta-analysis. Published online 2024. doi:10.1136/bmj-2021-067003
5.
Riley R, Tierney J, Stewart L, eds. Individual Participant Data Meta-Analysis: A Handbook for Healthcare Research. John Wiley & Sons; 2021.
6.
Sterne JAC, Sutton AJ, Ioannidis JPA, et al. Recommendations for examining and interpreting funnel plot asymmetry in meta-analyses of randomised controlled trials. BMJ (Online). 2011;343. doi:10.1136/bmj.d4002